
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- I18N
- 국제화
- gettext_windows
- coursera
- docker
- localization
- deeplearning.ai
- internationalization
- gettext
- Python
- 현지화
- AI
- andrew ng
Archives
- Today
- Total
JMANI
Lecture 5: Q-learning on Nondeterministic Worlds! by Sung Kim 본문
AI/Reinforcement Learning
Lecture 5: Q-learning on Nondeterministic Worlds! by Sung Kim
jmani 2022. 5. 20. 11:37link: https://www.youtube.com/watch?v=6KSf-j4LL-c&list=PLlMkM4tgfjnKsCWav-Z2F-MMFRx-2gMGG&index=8
- Deterministic VS Stochastic (nondeterministic)
- Deterministic: 이전의 Frozen lake처럼 일정한 결과를 내는 것
- Stochastic: 이전의 Frozen lake에 wind나 미끄러짐 같은 방해요소가 생겨서 일정하지 않은 결과를 내는 것
- Q의 영향을 줄임

- alpha 값을 곱해서 Q의 영향도를 줄이고 원래 가려던 계획의 영향을 높임
import gym
from gym.envs.registration import register
import sys, tty, termios
import numpy as np
import matplotlib.pyplot as plt
class _Getch:
def __call__(self):
fd = sys.stdin.fileno()
old_settings = termios.tcgetattr(fd)
try:
tty.setraw(sys.stdin.fileno())
ch = sys.stdin.read(3)
finally:
termios.tcsetattr(fd, termios.TCSADRAIN, old_settings)
return ch
inkey = _Getch()
# MACROS
LEFT = 0
DOWN = 1
RIGHT = 2
UP = 3
# Key mapping
arrow_keys = {
'\x1b[A': UP,
'\x1b[B': DOWN,
'\x1b[C': RIGHT,
'\x1b[D': LEFT
}
# Register Frozen with is_slippery False
register(
id='FrozenLake-v0',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name': '4x4'}
)
env = gym.make('FrozenLake-v0')
state = env.reset()
env.render() # Show the inital board
while True:
# Choose an action from keyboard
key = inkey()
if key not in arrow_keys.keys():
print("Game aborted!")
break
action = arrow_keys[key]
state, reward, done, info = env.step(action)
env.render() # Show the board after action
print("State: ", state, "Action: ", action, "Reward: ", reward, "Info: ", info)
if done:
print("Finished with reward", reward)
break
import gym
from gym.envs.registration import register
import sys, tty, termios
import numpy as np
import matplotlib.pyplot as plt
# Register Frozen with is_slippery False
register(
id='FrozenLake-v0',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name': '4x4'}
)
env = gym.make('FrozenLake-v0')
"""discounted reward"""
# Initialize table with all zeros
Q = np.zeros([env.observation_space.n, env.action_space.n]) # 16, 4
# Discount factor
dis = 0.99
num_episodes = 2000
# create lists to contain total rewards ans steps per episode
rList = []
for i in range(num_episodes):
# Reset environment and get first new observation
state = env.reset()
rAll = 0
done = False
# The Q-Table learning algorithm
while not done:
action = np.argmax(Q[state, :] + np.random.randn(1, env.action_space.n) / (i+1))
# Get new sate and reward from environment
new_state, reward, done, _ = env.step(action)
# Update Q-Table with new knowledge using learning rate
Q[state, action] = reward + dis * np.max(Q[new_state, :])
rAll += reward
state = new_state
rList.append(rAll)
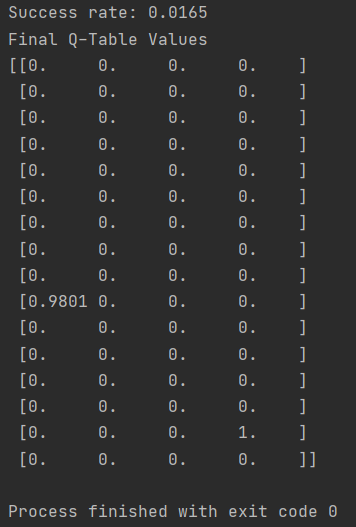
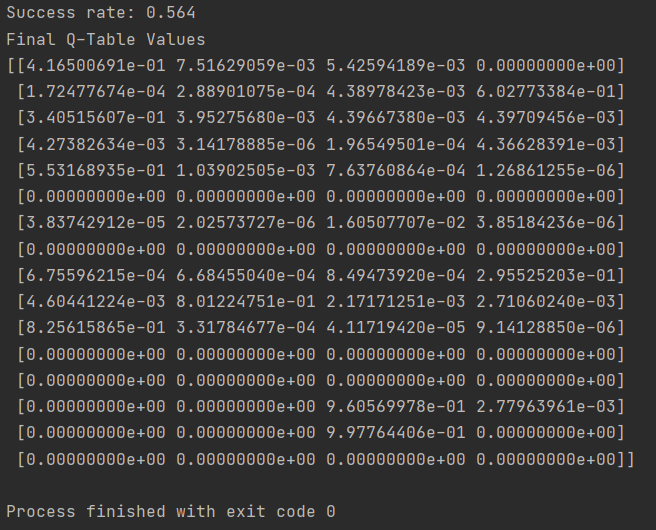
print("Success rate: " + str(sum(rList)/num_episodes))
print("Final Q-Table Values")
print(Q)
plt.bar(range(len(rList)), rList, color="blue")
plt.show()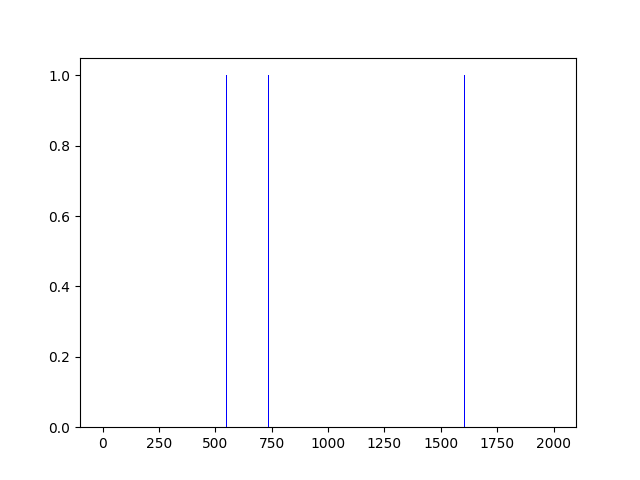
import gym
from gym.envs.registration import register
import sys, tty, termios
import numpy as np
import matplotlib.pyplot as plt
# Register Frozen with is_slippery False
register(
id='FrozenLake-v0',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name': '4x4'}
)
env = gym.make('FrozenLake-v0')
# """Q-learning algorithm in Nondeterministic Worlds"""
# Initialize table with all zeros
Q = np.zeros([env.observation_space.n, env.action_space.n]) # 16, 4
# Set learning parameters
learning_rate = 0.85
dis = 0.99
num_episodes = 2000
# create lists to contain total rewards ans steps per episode
rList = []
for i in range(num_episodes):
# Reset environment and get first new observation
state = env.reset()
rAll = 0
done = False
# The Q-Table learning algorithm
while not done:
action = np.argmax(Q[state, :] + np.random.randn(1, env.action_space.n) / (i+1))
# Get new sate and reward from environment
new_state, reward, done, _ = env.step(action)
# Update Q-Table with new knowledge using learning rate
Q[state, action] = (1-learning_rate) * Q[state, action] \
+ learning_rate*(reward + dis * np.max(Q[new_state, :]))
rAll += reward
state = new_state
rList.append(rAll)
print("Success rate: " + str(sum(rList)/num_episodes))
print("Final Q-Table Values")
print(Q)
plt.bar(range(len(rList)), rList, color="blue")
plt.show()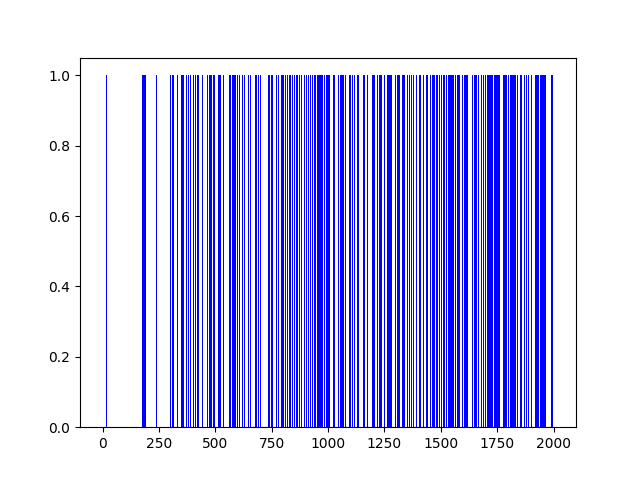
'AI > Reinforcement Learning' 카테고리의 다른 글
| Q-learning (0) | 2022.06.24 |
|---|---|
| Lecture 6: Q-Network by Sung Kim (0) | 2022.05.23 |
| Lecture 4: Q-learning (table) exploit&exploration and discounted reward by Sung Kim (0) | 2022.05.20 |
| Lecture 3: Dummy Q-learning (table) by Sung Kim (0) | 2022.05.19 |
| Lecture 2: Playing OpenAI GYM Games by Sung Kim (0) | 2022.05.19 |
'AI/Reinforcement Learning' Related Articles
more




Comments