
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 현지화
- coursera
- internationalization
- I18N
- docker
- gettext_windows
- deeplearning.ai
- 국제화
- andrew ng
- localization
- AI
- gettext
- Python
- Today
- Total
JMANI
YOLOX: Exceeding YOLO Series in 2021 본문
link: https://arxiv.org/pdf/2107.08430.pdf
1. Introduction
YOLO 시리즈는 실시간 어플리케이션을 위한 최적의 속도와 정확도 사이의 trade-off 관계(상충관계)를 추구해 왔다.
이를 위해 YOLOv2의 anchors, YOLOv3의 Residual Net 같은 당시 최고의 객체인식 기술을 구현했다.
그럼에도 불구하고, 최근의 YOLO 시리즈들은 최신 객체 인식 기술들을 도입하지 않고 있다. (e.g., anchor-free detectors, label assignment strategies, end-to-end(NMS-free) detectors)
저자는 YOLOv3-SPP(Spatial Pyramid Pooling)를 기반으로 위에 제시된 기술을 도입하고자 한다. YOLOv4와 YOLOv5는 anchor-based pipeline에 과도하게 최적화 되어 있기 때문에 배제되었다.

2. YOLOX
2.1. YOLOX-DarkNet53
Implementation details
- 300 epochs withe 5 epochs warm-up on COCO train2017Implementation details
- SGD(stochastic gradient descent)
- learning reate = lr * BatchSize/64 (lr=0.01 and cosine lr schedule)
- weight decay = 0.0005
- SGD momentum = 0.9
- batch size = 128 by defualt to typical 8-GPU
- input size = 448 to 832 with 32 strides
YOLOv3 baseline
흔히 알고 있는 YOLOv3-SPP는 DarkNet53 backbone과 SPP layer 구조를 가지고 있다.
저자는 기존 YOLOv3-SPP에 EMA weights updating, cosine lr schedule, IoU loss, IoU-aware branch를 추가했다.
또한, cls와 obj 학습을 위해 BCE Loss와 reg 학습을 위해 IoU loss를 사용한다.
이미지 증대를 위해서는 RandomHorizontalFlip, ColorJitter, multi-scale만 사용한다. RandomResizedCrop은 계획된 mosaic augmentation과 겹치는 부분을 발견하여 배제되었다.
Decoupled head
객체 인식에서 분류(classification)와 회귀(regression) 문제 사이의 갈등은 잘 알려져있다. 분류와 위치파악을 위한 decoupled(분리된) head 구조는 대부분의 one-stage, two-stage 탐지기에 널리 쓰인다. 하지만, YOLO 시리즈의 backbone과 feature pyramids(FPN, PAN)가 지속적으로 발전되면서 coupled(결합된) head가 쓰이게 되었다.
하지만, Decoupled head를 사용한다면,
(1) 수렴속도 향상
(2) end-to-end YOLO에 필수적
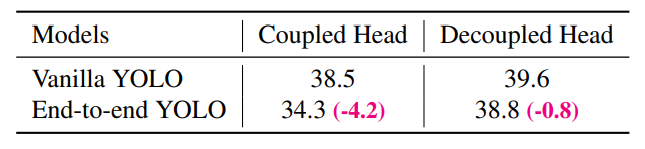
* end-to-end learning : 입력에서 출력까지 pipeline network 없이 한번에 처리하는 학습 방법
장점: 사람이 직접 feature를 추출할 필요 없음
단점: 메모리가 부족하거나 대량의 학습데이터가 없으면 사용X, 블랙박스, 문제의 원인 찾기 어려움

최종적인 구조는 다음과 같다.
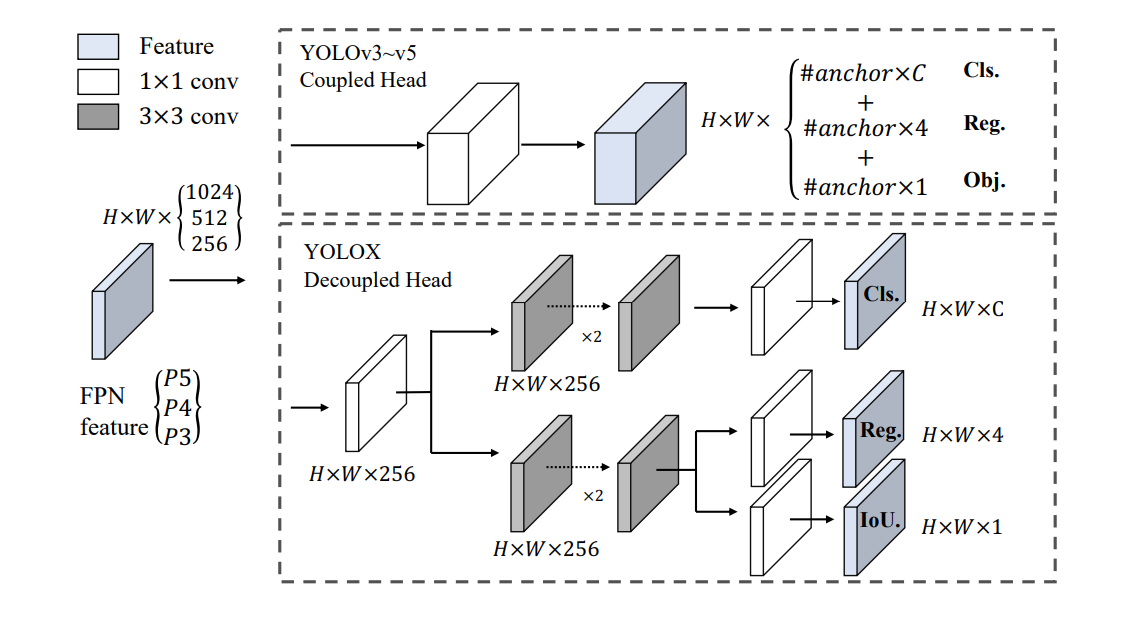
- 256 feature channel로 줄이기위해 1 X 1 conv layer를 포함
- classification과 regression을 위한 두개의 3 X 3 conv layer를 병렬로 연결
- regression에 IoU branch 추가
Strong data augmentation
저자는 데이터 증강을 위해 Mosaic과 MixUp 사용한다.
MixUp은 이미지 분류 작업을 위해서 설계 되었지만 객체 인식을 위해 BoF에서 수정되었다.
이러한 증강 방식을 채택한 후, ImageNet pre-trained(사전훈련)이 더이상 유익하지 않다는 것을 발견하여 처음부터 훈련시키게 되었다.
* MixUp: Beyond Empirical Risk Minimization
기존의 훈련 데이터셋은 모든 특성들을 포함하지 않기 때문에, 이로 학습된 모델은 갖고 있는 데이터셋에 편향되어 있다.(-->ERM: Empirical Risk Minimization principle) 이를 해결하기 위해, VRM(Vicinal Risk Minimization)이 등장. 이는 훈련 데이터셋만 학습하는 것이 아니라 그 근방(vicinal) 분포도 함께 활용하여 학습.
특징: 두 data와 label을 beta distribution에서 임의로 선택한 lambda로 convex combination하여 새로운 sample을 만듦.
장점: 부정확한 label이나 Multi-lable 문제에 적합
* convex combination: 집합 내분의 임의의 두 점을 연결하는 직선을 포함하는 집합(affine) & 계수가 양수이고 계수의 합을 1로 제한
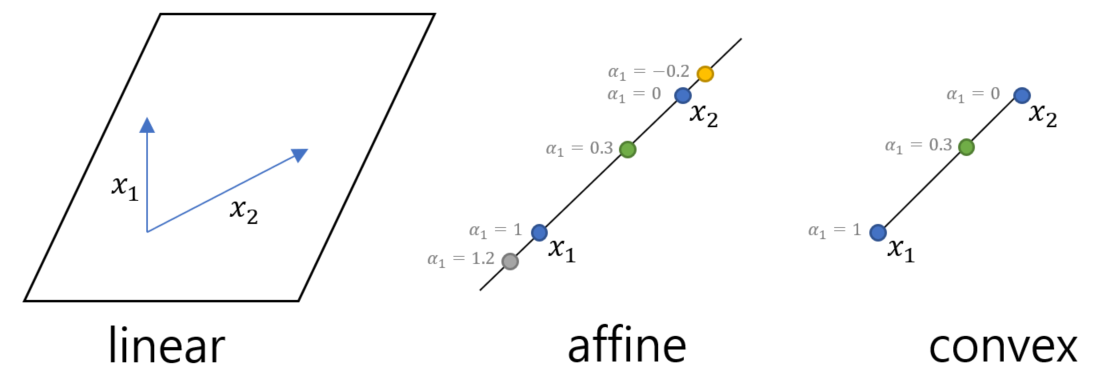

* Mosaic : 4개의 이미지를 하나로 합치는 방식
장점: batch size가 4배 커지는 것과 비슷한 효과를 볼 수 있어 작은 batch size에도 학습이 잘됨

Anchor-free
YOLO 시리즈는 모두 anchor-based pipeline을 가진다. 하지만 anchor 매커니즘에는 잘 알려진 문제가 있다.
(1) 학습시키기 전에 최적의 anchor setting을 위한 clustering 분석이 필요하다. 이는 domain에 따라 다르며 덜 일반적이다.
(2) 각 이미지의 예측된 수 뿐만 아니라 detection head의 복잡도를 높인다. 예를 들어, 전체 latency 측면에서 잠재적인 bottleneck 현상이 발생할 수 있다.
Anchor-free 매커니즘은 객체 인식 기술 분야에서 우수한 성능을 인정받아왔으며, heuristic tuning을 위한 parameter 수를 크게 줄여 detector, training, decoding 단계를 단순하게 만들 수 있다.
이는, 각 위치에 대한 예측을 3에서 1로 줄이고 그리드의 왼쪽 상단 모서리와 예측된 상자의 높이와 너비 측면에서 2개의 오프셋, 즉 4개의 값을 직접 예측하도록 한다. (이해X) 각 객체의 중심을 샘플로 할당하여 스케일 범위를 미리 정의한 뒤, FPN 레벨을 지정한다. 이는 detector의 매개변수와 GFLP을 줄여 더빠르고 정확한 성능을 보인다.
Multi positives
positive가 negative보다 훨씬 적은 불균형 문제를 해결하기 위한 기술이다.
FCOS에서 "center sampling"이라는 영역을 3 X 3만큼 positive로 할당하면 된다.
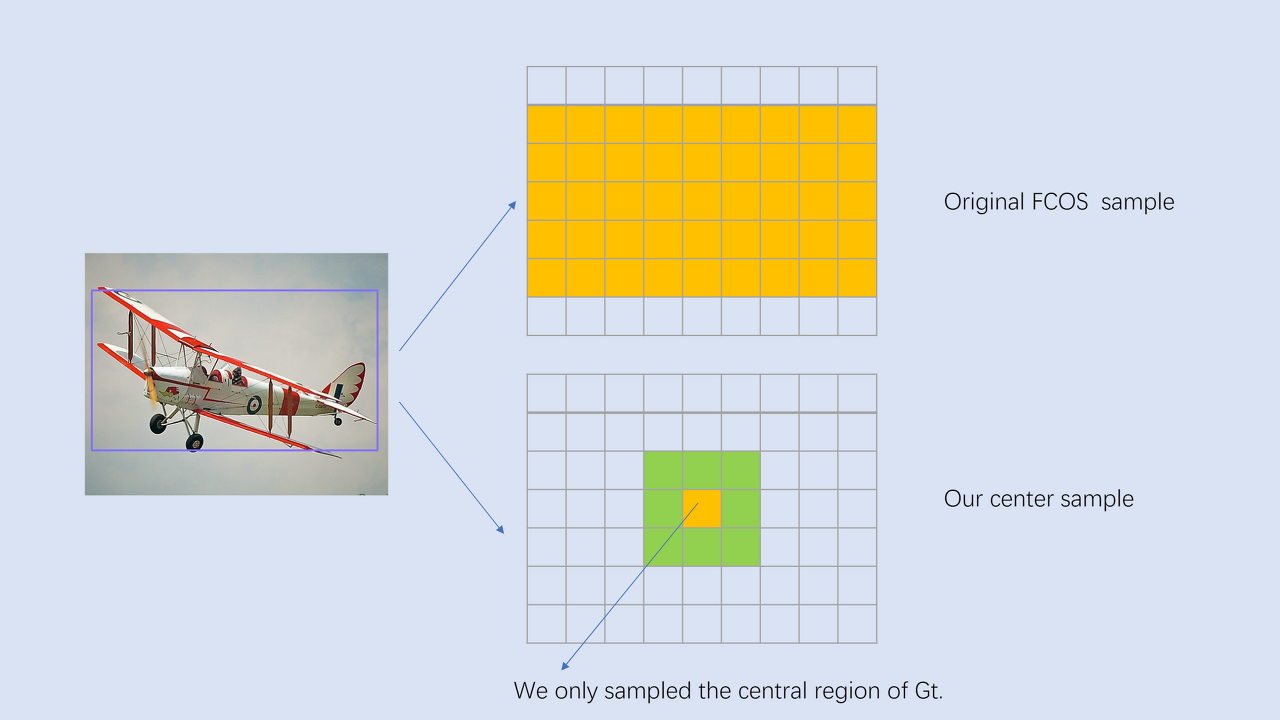
* center sampling: ground-truth의 중앙 부분만 positive으로 sampling
SimOTA
Label Assignment는 각 지점에 대하여 positive와 negative를 할당해주는 것이다. Anchor Free 방식은 GT의 중앙 부분을 positive로 처리한다. 이는 아래 사진처럼 여러 GT에 대해 positive로 설정된 모호한 anchor를 만들어 낸다.
저자는 이를 해결하기 위해 GT에 따라 anchor의 개수, 위치를 정해주는 OTA를 도입하고자 한다.
하지만, OTA 기술은 약 25%의 추가 학습 연산이 필요하기 때문에 Simple OTA를 적용시켰다.

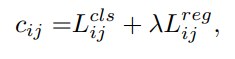
* OTA: Optimal Transport Assignment for Object Detection
* link: https://arxiv.org/pdf/2103.14259.pdf
SimOTA는 학습 시간을 줄일 뿐만 아니라 SinkhornKnopp algorithm의 부가적인 solver 하이퍼파라미터를 피할 수 있다.
End-to-end YOLO(NMS-free)
one-to-one label assignment와 stop gradient의 두개의 conv layers 추가
이는 end-to-end manner를 수행할 수 있지만, 성능과 추론 속도가 감소하여 최종 모델에는 포함하지 않고 옵션으로 남겨두었다.
2.2. Other Backbones
'AI' 카테고리의 다른 글
| Variational Autoencoders by 이활석(NAVER) (0) | 2021.11.04 |
|---|---|
| Data Scaler (0) | 2021.10.29 |